

著者:郎艶 時間:03.06.2020
2020年に世界を席巻した新型コロナウイルスは、人々の仕事生活に大きな影響を与え、世界のデジタル変革のために「早送りキー」を押した。これまで、多くの一般人は「ビッグデータ」や「デジタル化」について明確な概念を持っていなかったかもしれないが、この疫病は、国民にこれらの「ハイテク」を実感させた。例えば、アプリを通じてオンラインで健康的にカードを打つことで、企業と政府はビッグデータを利用して疫病追跡を行い、それによってより良い疫病予防制御を行うことができる。再稼働、再生産からクラウドオフィス、クラウド教育、クラウド問診まで、「デジタル化の新インフラ」は中国のこの防疫戦争の中堅であり、疫病との戦いの勝利に対して不滅の役割を果たしたと言える。
両会の開幕に伴い、「新インフラ建設」も政府活動報告書に書き込まれ、各業界はデジタル化の転換を強力に推進し始め、烈烈な「新インフラ建設」の大潮に加わった。では、「新インフラ」とは何でしょうか。以前私たちが理解していたインフラ建設は鉄道、道路などのインフラ建設であり、「新インフラ建設」は、5 G、超高圧、都市間高速鉄道と都市軌道交通、新エネルギー自動車充電杭、ビッグデータセンター、人工知能、工業インターネットの7つの分野を含む新しいインフラ建設であり、その本質は情報デジタル化のインフラ建設である。
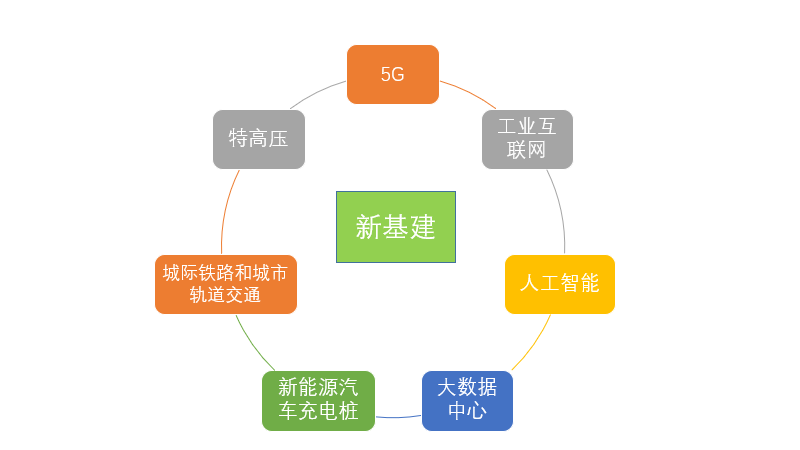
図1「新規インフラストラクチャ」の図解
情報デジタル化建設に至るまで、人工知能、ビッグデータは基礎となる核心技術として、新インフラ建設における他のいくつかの分野にも重要な支えとなっている。そして、「新インフラ」は「新」の字を際立たせ、自然と新しい技術が絶えず出現し、このような情勢の下で、知的財産権の保護活動も新たな発展のチャンスと挑戦を迎えた。これに基づいて、本文は「新インフラストラクチャ」における人工知能とビッグデータの知的財産権保護について簡単な分析を行った。
まず、人工知能とビッグデータ特許出願の傾向を見てみよう。下図2を参照すると、世界的には人工知能とビッグデータ分野の特許出願件数は全体的に年々上昇傾向にあり、2010年以降、人工知能とビッグデータ関連の特許出願件数の増加率は明らかに加速し、ここ数年の成長率はさらに注目されている(注:2019年と2020年の一部特許データは公開されていない)。2020年現在、世界の累計出願件数は20万件を超えている。「新インフラストラクチャ」の概念は新しいが、ローマは1日にして作られたものではなく、人工知能とビッグデータ分野における世界的な特許準備と配置はすでに形成されていることがわかる。
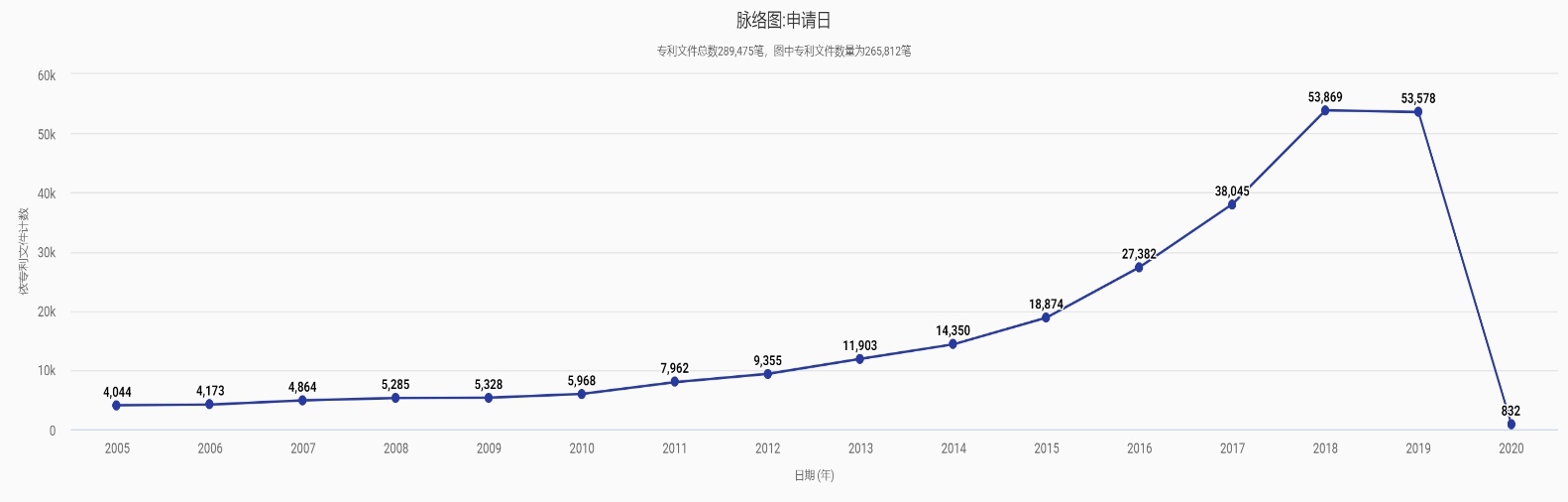
データはPatentcloudから
図2 人工知能とビッグデータ特許出願動向図
また、人工知能とビッグデータの知的財産権保護ルートをそれぞれ見てみましょう。
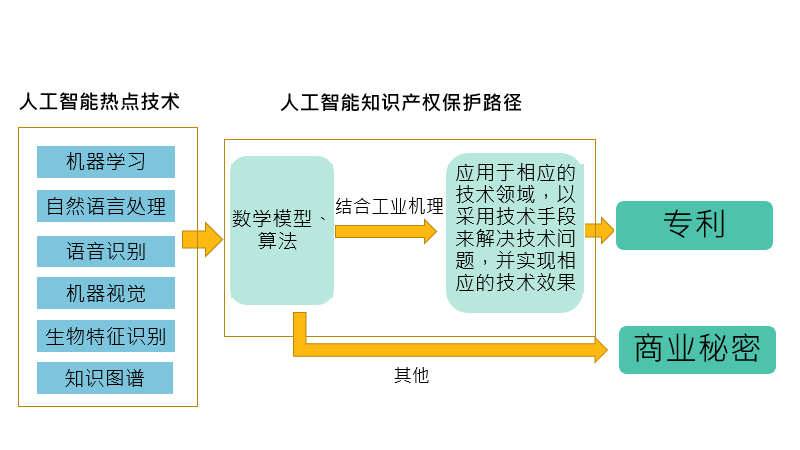
図3 人工知能知的財産権保護経路の図解
現在、人工知能のホットスポット技術は主に機械学習、音声認識、自然言語処理、機械視覚、生物特徴認識、知識マップなどを含む。人工知能技術の知的財産権を保護する最も一般的な手段は特許と商業秘密である。しかし、人工知能分野の技術的特徴は数学モデルとアルゴリズムの改善が多く、知的財産権保護にも一定の特殊性があることにある。
一方、人工知能分野におけるアルゴリズムと機械学習モデルについては、知的活動の規則と方法の範疇に属するが、特許法には明確な規定があり、知的活動の規則と方法は特許権を付与できない。そのため、アルゴリズムやモデルに関する特許を出願する際には、特許によるゲスト保護の問題に特に注意しなければならない。近年の人工知能分野の特許の発展態勢に対して、国家知識産権局も特に「特許審査ガイドライン」を改正し、2020年2月1日から施行した。改正後の『特許審査ガイド』は人工知能分野の特許の審査に対して比較的明確な審査基準を提供した:「審査は要求保護の解決方案、すなわち請求項に限定された解決方案に対して行わなければならない。審査において、簡単に技術特徴とアルゴリズム特徴あるいは商業規則と方法特徴などを切り離すべきではなく、請求項に記載されたすべての内容を一つの全体として、その中に関連する技術手段、解決する技術問題と獲得した技術効果に対して分析を行うべきである」。
実際の操作において、出願人は具体的な応用分野の工業メカニズムと結合して、アルゴリズムまたは学習モデルを具体的な技術分野に応用して特許出願を行い、技術手段を採用することによって技術問題を解決し、そして相応の技術効果を実現し、それによって特許保護客体の問題を回避することができる。しかし、具体的な応用シーンに結合することによって引き起こされる可能性がある問題の1つは保護範囲の縮小制限であるため、申請者はできるだけアルゴリズムとモデルの新しい応用シーンを拡張して、より包括的な保護を得ることを提案する。
一方、アルゴリズムと学習モデルにとって、権利侵害の立証は難しく、リバースエンジニアリングによって得られにくく、特許保護によって具体的なアルゴリズムとモデルを公開することは出願人にとって最良の選択ではないかもしれない。人工知能システムの訓練方法、アルゴリズムモデルについては、商業秘密の方法で保護するのが理想的な選択かもしれない。しかし、ビジネス秘密を保護する上で、企業はビジネス秘密の漏洩を防止するための強力な保護メカニズムを制定しなければならない。例えば、秘密保持契約の締結、ソフトウェアとアルゴリズム関連情報の授権流通などの方法で管理を強化することができる。
一方、人工知能技術は多くのソフトウェア開発に関連しており、出願人は著作権を登録することでコンピュータプログラムコードを保護し、ソフトウェアコードが他人に盗まれるのを防ぐこともできる。
次に、ビッグデータの知的財産権保護ルートを見てみましょう。
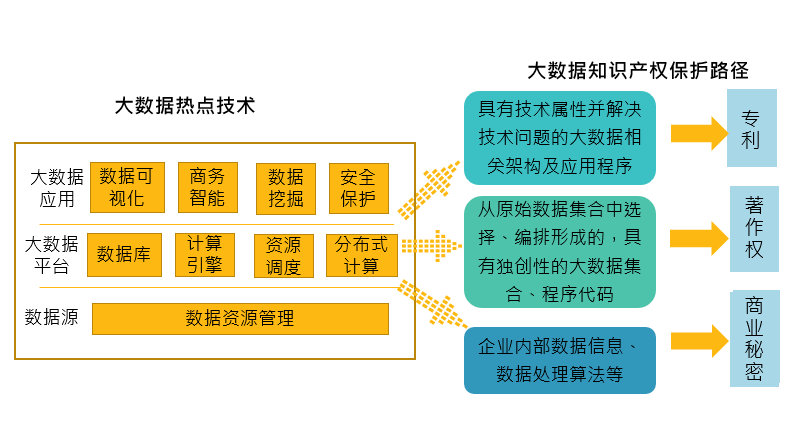
図4 ビッグデータ知的財産権保護経路の図解
現在、ビッグデータに関わるホットスポット技術は主にビッグデータ応用、ビッグデータプラットフォーム、データソースのいくつかの方面を含む。同様に、保護形態の面でも特許、商業秘密、著作権のいくつかの形式が主に含まれる。同人工知能技術と同様に、ビッグデータの保護にも特殊性がある。
一方、ビッグデータは一般的に商業方法、特定のアルゴリズム、データベースなどに関連し、上述の知的活動規則と方法にも帰属されやすいため、特許可能性がないため、企業はデータの編成、選択と計算を特許で保護できないことが多い。特許を出願するには、技術的属性を備える必要があり、同時に新規性、創造性、実用性を備える必要がある。技術的な属性を持ち、技術的な問題を解決するビッグデータ関連システム、アーキテクチャ、およびアプリケーションについては、特許出願が考えられる。一方、オリジナルデータ集合から選択、編成された、独創性のあるビッグデータ集合とプログラムコードは、著作権により保護することができる。一方、企業内の商業秘密に関するデータ情報、データ処理アルゴリズムなどは、商業秘密として保護することができる。
同時に、企業はビッグデータの革新に関わる上で、リスク回避にも注意しなければならない。まず、データ収集ネットワーク爬虫類は著作権侵害リスクを避けることに注意しなければならない。第二に、データの記憶と伝送の面で技術基準と著作権侵害の面でのリスクを避けることに注意しなければならない。また、ユーザのプライバシーデータを不正に取得することは、不正な競争を構成するリスクがある。





